
- 首 页
- 数据产品
-
土地利用遥感监测数据 点击更多
全球高精度土地利用数据服务 全国作物类型空间分布数据服务 二级分类土地利用数据30m 高精度植被类型分布数据 全国城市功能区划分布数据 全国DEM高程数据服务 全国耕地数据空间分布服务 全国林地分类数据空间分布服务 全国草地类型分类数据空间分布服务 全国水体数据空间分布服务 全国建设用地数据空间分布服务 全国未利用地数据空间分布服务 地形、地貌、土壤理化性质数据服务 全国坡度坡向数据服务 一级分类土地利用数据30m
全国气象气候数据服务 点击更多
全国降水量空间分布数据集 全国气温空间分布数据集 太阳辐射量空间分布数据集 全国气象站点观测数据集 全国平均风速空间分布数据集 全国平均水汽压空间分布数据集 全国蒸散量空间分布数据集 全国日照时数空间分布数据集 全国相对湿度空间分布数据集 全国地表温度空间分布数据集 全国气候区划空间分布数据集 全国气象站点空间分布数据集 全国土壤湿度空间分布数据集 全国水文站点地表径流量空间分布数据集
土壤理化性质数据服务 点击更多
土壤类型空间分布数据服务 土壤质地空间分布数据服务 土壤有机质空间分布数据服务 土壤酸碱度空间分布数据服务 土壤氮磷钾空间分布数据服务 土壤深度空间分布数据服务 土壤侵蚀强度空间分布数据服务 土壤含水量空间分布数据服务 土壤重金属含量空间分布数据服务 中国土壤阳离子交换量空间分布数据 中国土壤容重含量空间分布数据
社会经济类数据服务 点击更多
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国人口密度数据服务 全国poi感兴趣点空间分布数据 全国医院空间分布数据服务 全国学校空间分布数据服务 全国居民点空间分布数据 全国旅游景区空间分布数据 全国机场空间分布数据 全国地铁线路站点空间分布数据 人口调查空间分布数据服务 社会经济统计年鉴数据 中国各省市统计年鉴 中国县级统计年鉴数据 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政区划空间分布数据服务
卫星遥感影像数据服务 点击更多
Landsat陆地资源卫星影像 高分二号遥感影像数据 高分一号遥感影像数据 Sentinel2哨兵2卫星影像 SPOT系列卫星遥感影像数据 WorldView卫星遥感影像数据 资源三号卫星遥感影像数据 GeoEye卫星遥感影像数据 NOAA/AVHRR卫星遥感影像 MODIS卫星遥感影像 环境小卫星 Rapideye快鸟卫星影像
生态环境数据服务 点击更多
高精度归一化植被指数NDVI空间分布数据 高精度净初级生产力NPP空间分布数据 LAI叶面积指数空间分布数据 全国地表温度LST空间分布数据 全国生态系统服务空间数据集 全国湿地沼泽分类空间分布数据集 全国陆地生态系统类型空间分布数据集 全国农田生产潜力数据集 全国GPP初级生产力数据 全国农田熟制空间分布数据集 中国植被区划数据 中国草地资源数据 全国月度NDVI归一化植被指数空间分布数据 月度净初级生产力NPP空间分布数据 全国年度NDVI归一化植被指数空间分布数据 年度净初级生产力NPP空间分布数据 增强型植被指数EVI空间分布数据 RVI比值植被指数空间分布数据
-
- 数据检索
- 业务产品
- 免费专区
- 图书百科
- 行业新闻
- 关于我们
利用深度学习方法提取河南省冬小麦播种面积

小麦是中国最重要的口粮之一,小麦的播种面积及其产量直接关系到国家粮食安全和社会稳定。同时,小麦播种面积是开展小麦长势监测和估产工作的重要环节。随着遥感技术的发展,其为快速、准确提取小麦播种空间分布提供了有效手段。
本文利用ENVI深度学习图像分类工具,从39/43景10米分辨率的哨兵2卫星影像上提取河南省2018~2019年度、2019~2020年度冬小麦的播种面积。
1 冬小麦播种面积
提取结果如下所示:
|
年份 |
遥感提取面积 |
网上公布面积 |
差值 |
|
2018~2019年度 |
5926.49千公顷 |
5718.7千公顷 |
+3.6% |
|
2019~2020年度 |
5882.12千公顷 |
5700千公顷 |
+3.19% |

图:2019~2020年度冬小麦种植空间分布

图:2018~2019年度冬小麦种植空间分布
如下为几个局部提取的效果图:

图:平原地区

图:山地区域

图:耕地类型复杂区域
缺少验证数据,使用训练样本对深度学习训练模型做了验证,结果如下:
- 用户精度:94
- 生产者精度:91
- F1:924
所有操作是在ENVI5.5.3+ENVI Deep Learning1.1中完成,计算机环境为:DELL 7520笔记本电脑(CPU:i7-7700HQ,GPU:NVIDIA Quadro M2200, 4GB,内存:64GB),各个步骤时间如下表所示:
|
步骤 |
时间 |
说明 |
|
样本选择 |
10小时 |
采用面向对象分类方法获取样本,方法研究时间未计算。 |
|
训练模型 |
10小时 |
以2019年影像样本训练模型,模型直接应用于2020年。 |
|
图像分类 |
2019年:7小时40分钟 2020年:7小时 |
2019年43景影像(重叠覆盖面积多),2020年39景影像 |
|
分类后处理 |
30分钟内 |
镶嵌、裁剪、小斑去除。 |
计算机处理部分总共时间为:35小时左右。
2 影像数据
影像数据是3月份成像的、欧空间发布的哨兵2数据,云量在1%内。
 |
 |
图:左侧2020年(39景),右侧2019年(43景)
3 技术流程
技术流程如下:

本次冬小麦面积提取并未对哨兵数据进行预处理,对数据进行归一化处理对提取精度可能有帮助。
4 操作步骤
本次提取河南省冬小麦面积,使用哨兵2号卫星影像,选取Blue、Green、Red、NIR 10米分辨率4波段进行冬小麦提取。
4.1创建标签图像
进行深度学习的第一步是创建标签图像,ENVI提供多种方法获取样本从而生成所需的标签图像。

进行深度学习的第一步是创建标签图像,ENVI提供多种方法获取样本从而生成所需的标签图像。
(一)样本区域选择
由于河南省面积广阔,地域差异较大。选取哪些区域进行样本获取也需要进行综合考虑,使模型可以适应河南省不同地域的影像特点,因此选择河南省中部、北部、南部、东部、西部地区单景哨兵2号数据作为样本区域,获取样本。

图:样本选择影像分布
(二)样本绘制
考虑样本选择区域较大,人工目视解译工作量较大,这里使用ENVI面向对象分类结果作为样本数据。
在ENVI工具箱中选择Feature Extraction/Rule Based Feature Extraction Workflow,使用ENVI FX工具分别对5景影像进行面向对象分割,并根据每幅影像的特点建立不同提取规则,提取冬小麦种植区域。

图:建立分类规则
其中每景影像的规则需要分别进行单独的光谱分析获取。分析方法如下:
- 在ROI样本绘制工具中分别绘制不同类型的样本:不同长势冬小麦、蓝顶房屋、森林植被等各类样本。
- 绘制好样本之后,右键选择Statistics分别对不同样本进行光谱统计分析,根据不同样本的光谱范围差异获取提取阈值,之后在FX中建立规则提取冬小麦。

图:获取分类规则
最终根据不同规则分别提取5景影像的冬小麦种植面积。
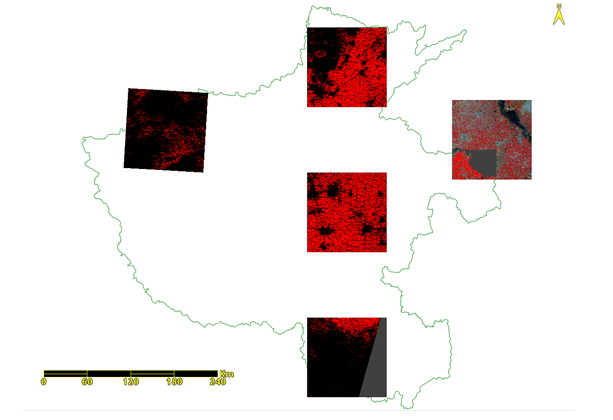
图:样本提取结果
(三)生成标签图像
通过面向对象分类方法分别获取5景影像的冬小麦种植区域作为样本,使用Deep Learning/Build Label Raster form Classification工具生成标签栅格进行深度学习模型训练。
4.2训练深度学习模型
有了标签栅格可以在ENVI工具箱中,选择Deep Learning/Train TensorFlow Model,即可进行深度学习模型训练。

图:模型训练
- 在Train TensorFlow Mask Model面板中,点击Input Model下方的New Model初始化一个深度学习多类别提取模型,Number of Bands设置为4波段,Number of Classes设置为1类,其他参数按照默认设置,点击OK。
- 在Training Raster选项中选择创建好的5景Label Raster,同样在Validation Raster中选择相同的5景Label Raster,其它参数按照默认设置。
- 分别设置Output Best Model和Output Last Model的输出路径及文件名,点击OK开始训练深度学习模型。
4.3模型分类
使用训练好的模型分别对河南省2019年43景和2020年39景10米分辨率哨兵2号数据进行冬小麦提取。使用ENVI Modeler建立批量分类工具。

图:ENVI Modeler深度学习批处理分类工具
运行批处理工具,在参数输入面板,输入要提取哨兵数据,模型选择上一步中训练好的H5模型(Best Trained Model),设置输出路径、分类文件文件名和类激活文件文件名,点击OK即可进行深度学习模型分类。

图:深度学习批处理工具
4.4分类后处理
分类后处理主要包括结果镶嵌、裁剪、小图斑处理、分类后编辑。
- 结果镶嵌
使用Mosaicking/Quick Mosaic工具,在弹出的参数对话框中Input Raster选择冬小麦分类文件,Data Ignore Value设置为0,设置输出路径和文件名,点击OK进行镶嵌处理。
- 结果裁剪
使用Region of Interest/Subset Data from ROIs工具,利用河南省行政边界矢量对镶嵌好的冬小麦分类文件进行裁剪。
- 小图斑处理
使用Post Classification/Majority/Minority Analysis工具,在Classification Input File对话框中选择裁剪后的分类文件点击OK,在Majority/Minoruty Parameters对话框中,Select Classes选择要进行小图斑处理的类别名称,Kernel Size设置为9,其它按照默认设置,设置输出路径及文件名,点击OK即可进行小图斑处理。
对于耕地与其他地物类型邻接的混合像元,可以再通过膨胀腐蚀操作滤除或保留。本次冬小麦提取结果滤除耕地与其他类型邻接的混合像元。使用Filter/Convolutions and Morpholopy工具,在弹出的对话框中点击Morphology选择Erode做腐蚀处理,Kernel Size选择3×3,其他按照默认设置点击Apply To File。在Morphology Input File对话框中选择上一步处理的结果,点击OK,在弹出的对话框中选择输出路径和文件名,点击OK进行处理。
- 分类后编辑
将冬小麦提取结果叠加到影像图上,使用ENVI分类编辑工具对错分、漏分像元进行编辑。本文没有对结果做编辑。




